

Trong bài viết này, tôi sẽ tập trung vào việc triển khai AI trong các công ty và quy mô lớn. Những AI này cần sử dụng nhiều dữ liệu từ cơ sở dữ liệu của công ty, cả trong quá trình huấn luyện và khi sử dụng các yêu cầu để làm phong phú thêm các yêu cầu (RAG: Retrieval Augmented Generation).
Vì các cơ sở dữ liệu và các nguồn khác như tệp, hồ sơ, v.v., thường không đồng nhất và chất lượng khác nhau, việc kết nối AI trực tiếp với các khu vực lưu trữ này là nguy hiểm. Thông minh hơn là xây dựng một tầm nhìn thống nhất về tất cả dữ liệu của công ty bằng cách sử dụng một mô hình kinh doanh mạnh mẽ nằm trước các khu vực lưu trữ không đồng nhất. AI sau đó có thể lấy dữ liệu từ nguồn sạch, đi kèm với các quy tắc bảo mật.
Các nền tảng phần mềm tồn tại để thiết lập hệ thống loại này, hoặc với cách tiếp cận cơ sở dữ liệu hướng đồ thị hoặc với cơ sở dữ liệu NoCode mà chúng tôi thường trình bày trong các buổi Zoom hàng tuần “AI by Drinkizz”. Nhưng bất kể công nghệ nào được sử dụng, cần có nỗ lực mô hình hóa để đạt được tầm nhìn thống nhất của dữ liệu. Nó cũng cần được thực hiện theo cách cho phép nó phát triển để theo kịp những thay đổi trong kinh doanh xảy ra thường xuyên. Do đó, mô hình phải rất rõ ràng và nghiêm ngặt trong quản lý chất lượng, nhưng cũng đủ tốt để chấp nhận các mở rộng mà không phải xem xét lại tất cả.
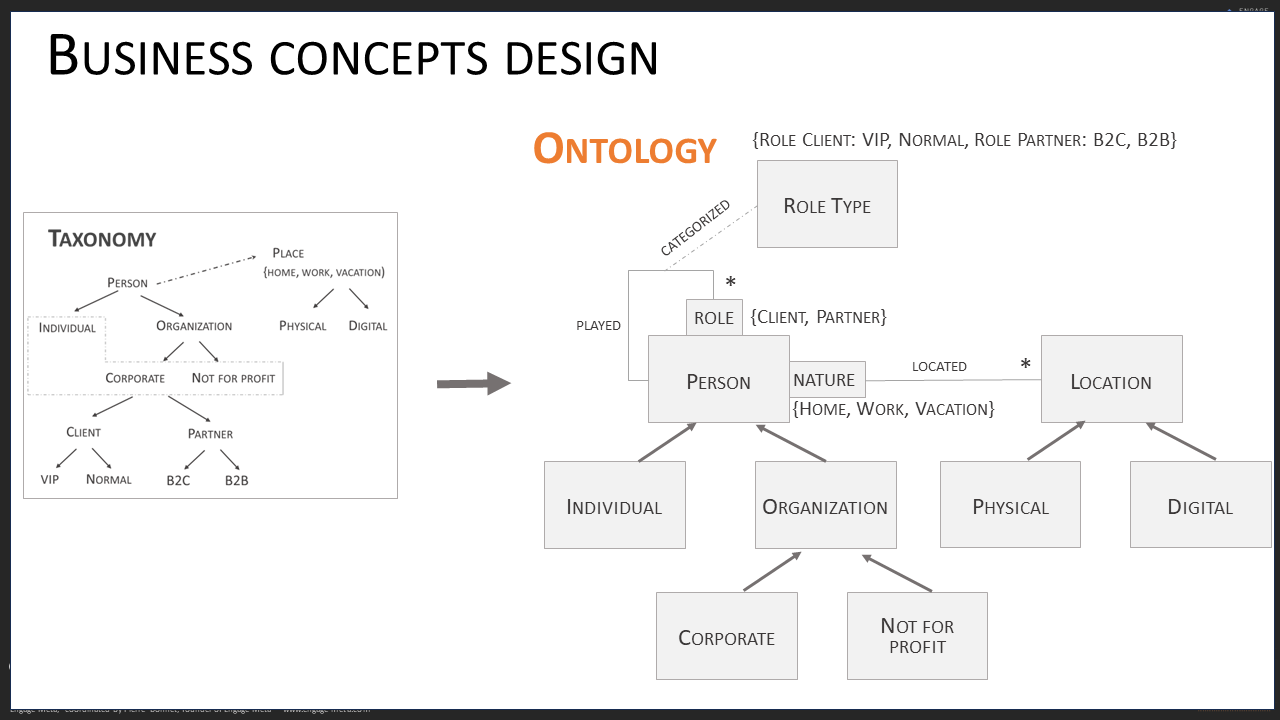
Việc mô hình hóa này đòi hỏi chuyên môn trong việc xây dựng hệ thống phân loại (ontology), còn được gọi là nghệ thuật mô hình hóa ngữ nghĩa. Ontology là nghệ thuật ghi lại các khái niệm kinh doanh của công ty và định nghĩa các mối quan hệ của chúng cũng như các quy tắc kiểm soát chất lượng của chúng. Hãy cùng xem xét kỹ hơn bây giờ.
Trước hết, một khái niệm kinh doanh là một thực thể quản lý chính cho công ty, chẳng hạn như Khách hàng, Nhà cung cấp, Hóa đơn, Đơn vị sản xuất, v.v. Một startup có khoảng mười lăm khái niệm này, một SME có hơn hai mươi, và một công ty lớn thậm chí còn nhiều hơn. Mỗi khái niệm kinh doanh được định nghĩa để tạo thành một thuật ngữ được chia sẻ bởi toàn bộ công ty. Nó đi kèm với một từ điển thuật ngữ để chuẩn hóa các thuật ngữ tương đương.
Tiếp theo, các khái niệm kinh doanh được tổ chức thành một hệ thống phân cấp mô tả các cấu trúc cha-con tồn tại giữa chúng. Ví dụ, một Khách hàng được chuyên môn hóa trong các thị trường B2B, Bán lẻ, v.v.
Khi đã có hệ thống thuật ngữ, phân loại và phân cấp, đến lúc mô hình hóa các thuộc tính của các khái niệm kinh doanh và chỉ định các mối quan hệ giữa chúng. Sức mạnh ngữ nghĩa của mô hình dữ liệu phụ thuộc rất nhiều vào chất lượng của việc mô hình hóa các mối quan hệ giữa các khái niệm kinh doanh. Lần đầu tiên bạn thực hiện mô hình hóa ngữ nghĩa, hãy được hỗ trợ bởi một chuyên gia trong lĩnh vực này, ít nhất để xác minh rằng mô hình của bạn là vững chắc. Bạn cũng có thể sử dụng một trợ lý AI để mô hình hóa dữ liệu, nhưng bạn sẽ cần huấn luyện nó tốt trước khi nó có thể giúp bạn hiệu quả (hãy gọi cho chúng tôi nếu bạn cần hỗ trợ cho hoạt động này).
Cuối cùng của quá trình mô hình hóa ngữ nghĩa, bạn sẽ xây dựng các hệ thống phân loại của mình. Tại giai đoạn này, nó vẫn là một tầm nhìn tĩnh của dữ liệu thống nhất. Một bước mô hình hóa cuối cùng là cần thiết để thêm một khía cạnh động hơn. Mục đích của nó là kiểm soát chất lượng của dữ liệu được chứa trong các khái niệm kinh doanh. Đây là các định lý được thêm vào ontology.
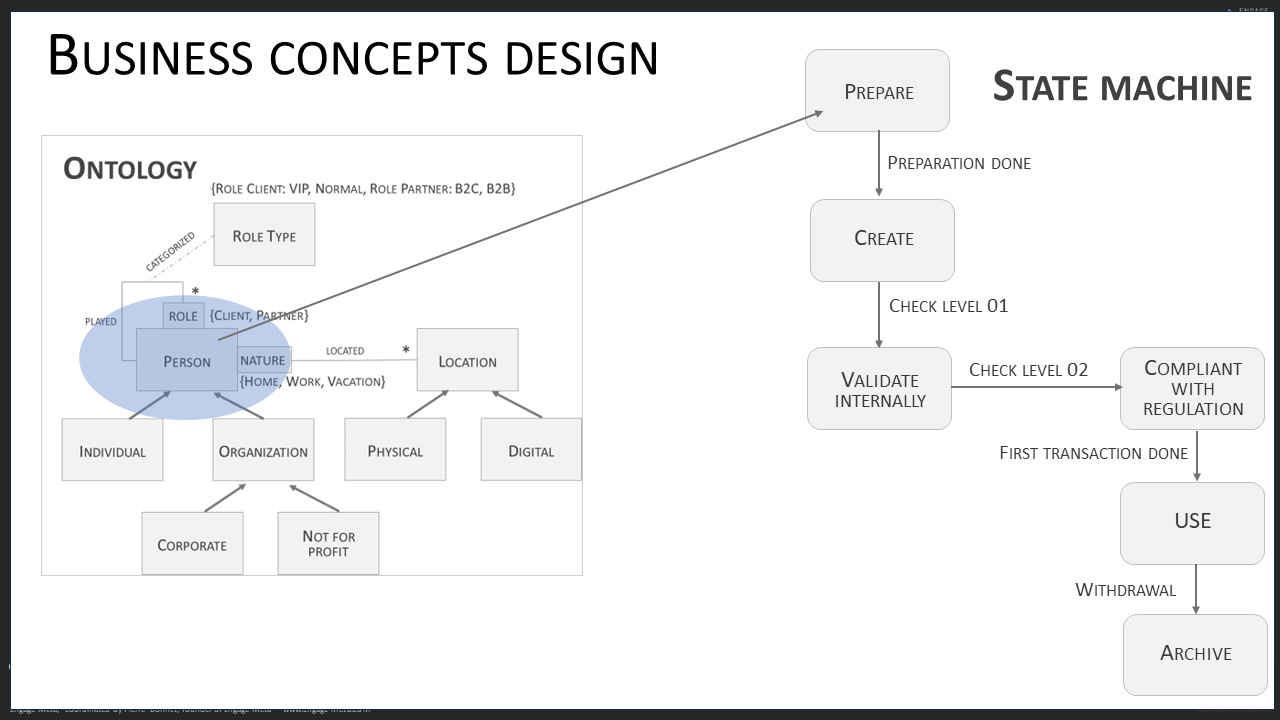
Ở đây, tập trung vào các quy tắc kiểm soát chung không phụ thuộc vào các lựa chọn tổ chức. Một cách mạnh mẽ để chính thức hóa các định lý kinh doanh này là sử dụng các máy trạng thái. Ví dụ, một khái niệm kinh doanh Sản phẩm có thể có danh sách các trạng thái có thể như: R&D, Danh mục chào bán, Bảo trì, Ngừng bán… Tùy thuộc vào trạng thái của một sản phẩm (thực thể của khái niệm kinh doanh Sản phẩm), các hành động cập nhật, xóa và sử dụng là có thể hoặc không.
Danh sách các lợi ích chính của việc có các hệ thống phân loại được xây dựng tốt:
- Chúng cho phép triển khai một lớp dữ liệu thống nhất trước các cơ sở dữ liệu không đồng nhất của bạn, hoặc nếu bạn bắt đầu từ đầu, để có một cơ sở dữ liệu rất sạch sẽ theo kịp sự phát triển của doanh nghiệp mà không tạo ra sự hỗn loạn cho việc lưu trữ dữ liệu. Cách tiếp cận này tạo ra một bản sao số của IT của bạn mà bạn có thể kết nối AI của mình cả để huấn luyện và để tăng cường các yêu cầu (RAG) bằng cách truy xuất dữ liệu thời gian thực trong các hệ thống phân loại được vector hóa.
- Chúng cung cấp sự phân loại cần thiết để tổ chức kiến thức, vượt ra ngoài dữ liệu từ cơ sở dữ liệu. Để huấn luyện AI của bạn tốt hơn, bạn sẽ cần chính thức hóa kiến thức ngầm của tổ chức của bạn, tức là những gì đội ngũ của bạn biết nhưng chưa được ghi chép hoặc giải thích rõ ràng. Tất cả kiến thức rõ ràng sau đó được nạp vào các hệ thống phân loại để bổ sung dữ liệu cấu trúc, do đó tăng cơ sở kiến thức được sử dụng bởi AI.
- Trong quá trình thực hiện yêu cầu, truy cập thời gian thực vào các hệ thống phân loại cho phép làm giàu ngữ cảnh yêu cầu ngay lập tức, giúp AI làm việc tốt hơn. Đây là nguyên tắc của RAG, mà tôi đã đề cập nhiều lần trong bài viết này.
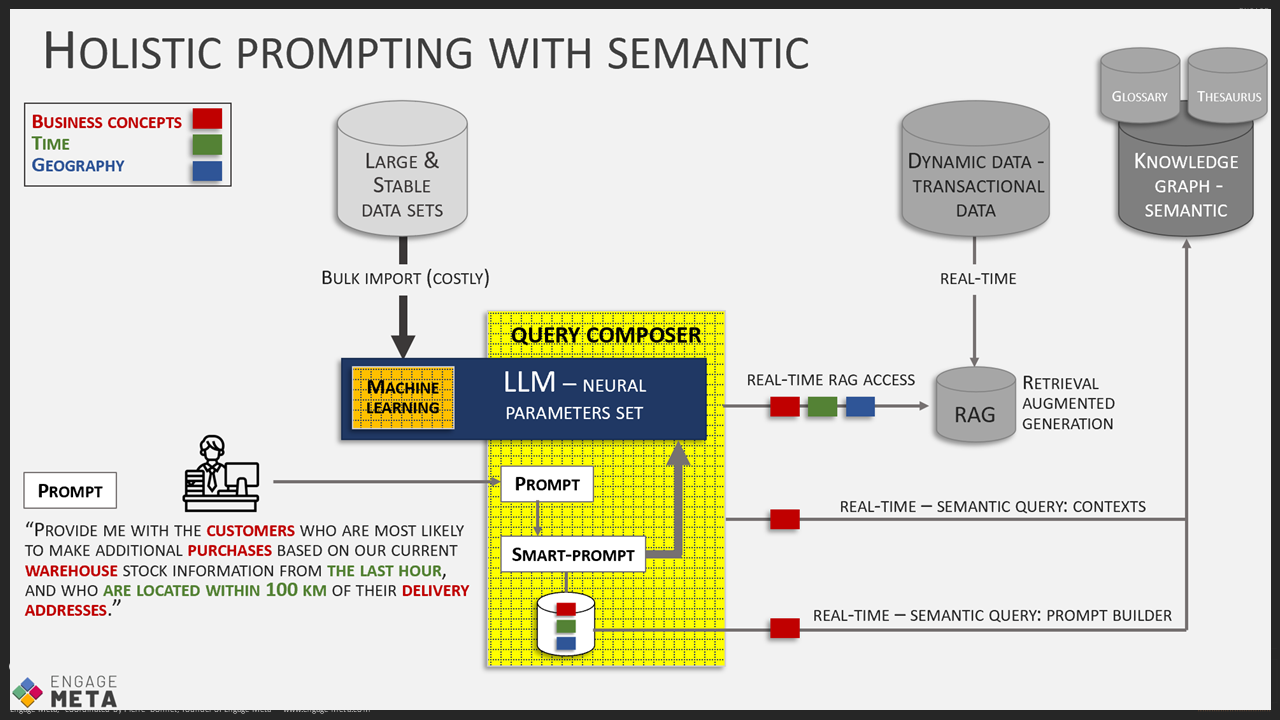
- Ngược lại, trong quá trình tiếp nhận phản hồi do AI tạo ra, việc truy cập vào các hệ thống phân loại sẽ cho phép kiểm tra chất lượng của kết quả, ví dụ, bằng cách kiểm tra các nguồn dữ liệu được sử dụng. Điều này giảm đáng kể các tác động tiêu cực của ảo giác khi AI không được sử dụng trong ngữ cảnh sáng tạo mà thay vào đó là để phân tích xác định.

Bây giờ bạn đã biết lý do tại sao bạn cần các hệ thống phân loại với AI của mình. Lưu ý rằng nếu bạn đang khởi nghiệp, cơ sở dữ liệu NoCode với hệ thống phân loại là cách đúng đắn để đi. Nếu bạn đã có một thiết lập hiện có, bạn vẫn cần các hệ thống phân loại, nhưng có thể với một lựa chọn công nghệ hướng đến NoCode và cơ sở dữ liệu hướng đồ thị. Tùy thuộc vào phạm vi IT hiện có của bạn, bạn sẽ cần xem xét kiến trúc dữ liệu tốt nhất. Tôi mời bạn tham khảo khung công việc TRAIDA (Transformative AI and Data solution) từ cộng đồng của tôi tại www.engage-meta.com để biết thêm thông tin về kiến trúc này.
VẬY TIẾP THEO LÀ GÌ?
Nếu bạn có tham vọng sử dụng AI trong công ty của mình với các kết nối tới các ứng dụng và cơ sở dữ liệu của bạn, tôi khuyên bạn nên bắt đầu huấn luyện về mô hình hóa ngữ nghĩa ngay lập tức. Bạn chắc chắn sẽ cần nó. Hãy gọi cho chúng tôi để được đào tạo dựa trên trường hợp sử dụng thực tế của hành trình mô hình hóa dữ liệu của Drinkizz.
Bạn cũng có thể mua cuốn sách của tôi, META-Entrepreneur, có sẵn bằng tiếng Pháp, tiếng Anh và tiếng Việt, bằng cách truy cập www.engage-meta.com.
Ngoài ra, bạn có thể thử các sản phẩm từ startup Drinkizz, nơi tôi và các đồng sáng lập của tôi áp dụng các nguyên tắc của WASI.
Hẹn gặp lại bạn sớm!”
Liên kết hữu ích
Nước uống năng lượng tự nhiên hữu cơ từ Drinkizz: O.N.E Drink (Organic Natural Energy) – Drinkizz Shop
Đào tạo Drinkizz : Phiên đào tạo – Drinkizz
Năng lượng tốt không chờ đợi!
Pierre Bonnet



